Software engineer — from monolith to cloud: think small
A 9 minutes story written on Oct 2017 by Adrian B.G.

The new architecture types are more complex, but from a developer point of view, it’s easier. Either way, we must change our mindset: we need to think small to create large systems (see Linux as an example).
From monolith to cloud series 🌩
A series of articles designed to help developers switch from a monolith to a cloud mindset. The web is full of very good tutorials and examples on Why and How to make the switch, so I decided to focus on the small details.
- Auto Increment to UUID
- Think small - this article
I found a video that describes the software evolution in the last 20+ years, from monolith to amazon microservices, I highly recommend it for a deeper understanding on the subject:
Let’s recap how the software architecture of the apps evolved over time:
- Write an app for each architecture
- Same source code compiled to many architectures (compilers and C)
- Monolith: 1 app with 1 running instance and 1 database instance
- Distributed: 1 app with multiple instances and/or 1-n DBs
- Services: multiple apps, 1 or more instances and 1 or more DBs. You split the monolith into more (still big) apps so you can split the work.
- Microservices: many small (context) apps with n instances. Each module in a monolith is now a standalone service that can be scaled.
- Functions: stateless pieces of the app that can scale automatically, see AWS Lambda and Google or Azure functions.
This article is addressed to the developers that want to migrate to 5, 6 and 7.
You can see the pattern here, the software architecture evolved to smaller and smaller components if you saw the previous video you learned about the advantages gained by doing so.
Like parallel computing, if you split a big problem into multiple solvable pieces you can solve it in a fraction of the time with more teams.

Smoother learning curve
Thinking small is easier than big. It’s easy to be productive in a small team, because you do not have to understand the entire application to add new features or fix old ones, only one module/service. The best example is when you have a new team member, it can reach the productivity phase faster == he/she only needs to know one service to get started.
Smaller thoughts, but many
Microservices are not issue free, it has its own pitfalls and problems. For example, some teams treat their services as immutable, instead of api/v2/ they make a new service. It’s common for big companies to have more than 1000 of them. You usually need an entire team just to orchestrate the microservices.
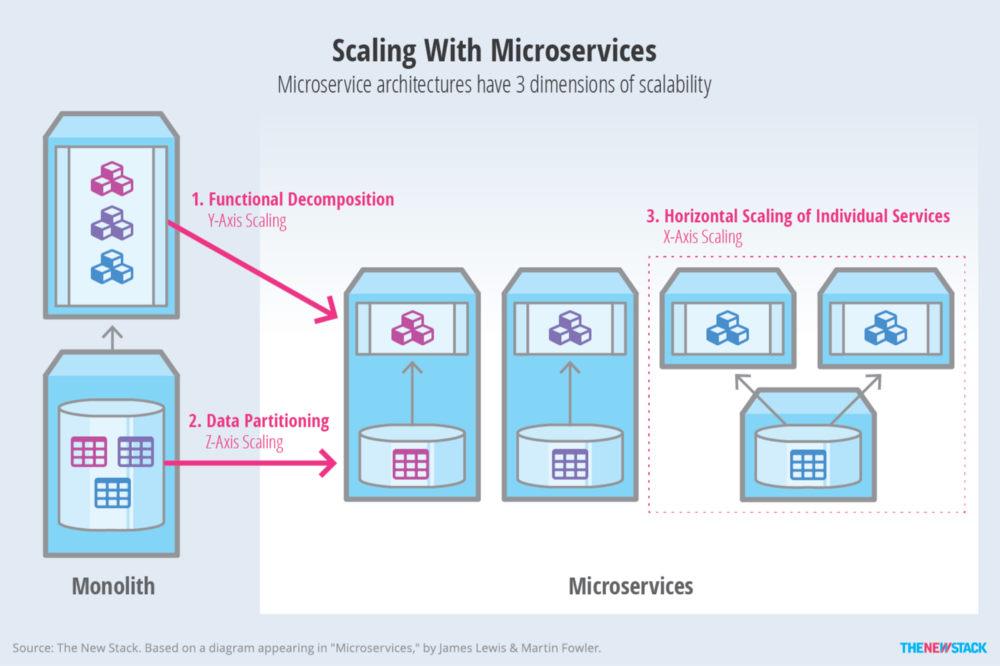
Smaller data
The new architecture doesn’t affect only the code of your apps, but the data storage too. Each service can have its own data storage that can be scaled as needed. Most likely you will need other storage like [BigTable] (https://cloud.google.com/bigtable/) or DynamoDB to aggregate the data from the services databases for analysis and analytics.
One is many
Your modules were single (running) instanced in the monolith production environment, now each of them has 1-n instances. You cannot have state anymore, you cannot trust one single instance of a service, you have to presume it will be closed at any time by the container orchestrator.
More instances of a module add more complexity to other adjacent systems like monitoring, user persistent sessions etc.
Smaller containers
Most likely you are using dedicated servers, VPS and Virtual machines to develop and run your application. If you want to scale you need to change that to a smaller unit: containers. I recommend the following switching to the following technologies:
Docker images to store your apps, settings, services (MySQL etc) and development setups. Instead of installing a service/app/daemon on your system directly, Docker uses a kernel virtualization technique to separate each app in its own environment. There are many benefits for doing this, example avoiding system pollution with different libraries versions (python 2,3 or ruby 1.8 and 1.9) and you can easily run multiple instances of the same services on different ports.
You will also want to switch to Kubernetes to orchestrate your apps and dependencies. It has many useful features builtin like: service discovery, load balancing, rollouts and rollbacks, handing secret configs and self-healing and managing batch/CI tasks.
Using Kubernetes you will design your infrastructure at a higher level of abstraction, you do not have to worry about machines, SSH, ips and firewalls anymore. It works seamlessly with Google Cloud but you can setup a cluster using any hosting provider (AWS, Digital Ocean).
Another side-effect of using an orchestrate like Kubernetes is that you will not have the 1 Machine == 1 service relationship anymore. You do not know or care which container runs on which machine. The virtual machines/servers are treated as pool resources and used as Kubernetes sees fit.
A good side effect of the automatic balance of the containers is that you will use fewer machines with a higher load of usage, reducing the costs.
Smaller contracts
Each module you are extracting from the monolith must have a contract too, an interface, some rules that it must respect in order to communicate with the others. Usually, it is a RESTful JSON API or a gRPC faster pipeline.
In a monolith, you were doing contracts using Interfaces, Observer and messaging patterns. Now you have different apps that need a way to discover the other modules and communicate with them. You will have to do some research based on your use case and technologies you want to use.

Instead of 1 big bear now you have to care for many smaller ones
Smaller scope but more responsibilities
If you are a developer working with a monolith, it is not expected of you to fix or even understand the bigger picture, especially how the Operations are done. There are some projects in which you cannot even replicate a production env on your local development setup, the hurdle is too great that you need a squad to maintain it.
Old way: It is not expected of you to “care” about your code on production. DevOps and special developers are in charge to be on call and fix your code. Everyone is just a small cog in a huge system.
New way: But now, with services and smaller projects you can (and should) take responsibility for your actions (writing features) and be on call. Especially as a full stack web developer you can now take charge when something happens on production. Because the project is smaller:
- you are used to the production environment, it’s small so you can replicate it on your local machine
- you can do automatic tests with more coverage
- you can be on call, react and solve the problems faster than an outsider could ever do
- you have code insights and can optimize the infrastructure, take some out of the DevOps and Architect responsibilities. See it like this: if a manufacturer 🍏can build its own hardware and software, it will work better when combined.
Don’t worry, usually the “on call” duties are distributed in a Round Robin fashion, each day or sprint the next developer is chosen.
All these and more add up to your responsibility as a developer, but I think it’s great, it’s an advantage and we will become better software engineers by doing so.
No more shortcuts
Do the following scenarios sound familiar to you?
- connecting through an FTP to add debug statements in a production env
- cache values to the local machine (RAM)
You cannot do these “bad practices” anymore in a distributed architecture. Let me give you an example.
The user logins by an HTTP request to server A, you store the login session token/credentials in the local memory, if the next HTTP request is sent to another server instance (B) by the LB (load balancer), but the user is not logged on that machine, its credentials are in server A’s memory. You can see from this simple example why you cannot use the local storage in a distributed env.
These simple scenarios are usually fixed using a Key/Value distributed storage like Memcached/Redis, from which all the servers can read/write data. You basically move the STATE of your app to a storage system that can be scaled as well.
If you want to debug an user you can modify the source code manually on server A, but the LB may send the request on server B …
Outsource the provisioning
If you split your monolith you will have more (smaller) apps, that means you will have more deployment scripts, servers and networks to worry about. This is where the “serverless” providers come in handy, like AWS, Google Cloud and Azure. Instead of hiring more DevOps you can benefit from their services. You can use them for specific services or go all in and rely fully on their “cloud” services.
PS: I hate the words “cloud” and “serverless”, the only technology that has a close resemblance to this terms is the “blockchain”. A cluster of machines in a building is anything like the clouds in the sky.
Be careful what you wish for
Microservices and functions come with a big overhead, you may end up working more on the infrastructure than your actual app. All the successful examples of micro-services have behind them a multi-million $ company.
I would suggest a natural evolution, split the monolith into few services step by step. Export the intensive functionalities to smaller containers/functions so you can scale.
Other resources
- Later addition (after publish): I have found a very similar (with this post) video about migration to the AWS Lambda functions (or Google functions), with a focus on the economic advantages and how does it affect our mindset.
- Update 20 Nov 2017: A nice simple story of why and when do you need the “cloud”, [how, why and when Netflix switched to AWS] (https://youtu.be/EDZBYbEwhm8)and how did they split their monolith into microservices and now to lambda functions.
- Software engineer — from monolith to cloud: Auto Increment to UUID
- Meetup.com switched from a monolith to the cloud and their CTO explained what were the steps and struggles: Meetup Architecture with Yvette Pasqua
- Microservices are hard — an invaluable guide to microservices.
- Even banks can benefit from this new environment, see the technical story of a newly created UK bank: Banking on Go — Matt Heath — SF Docker + Go Meetup.
A few conference panels about microservices:



