Software engineer — from monolith to cloud: Auto Increment to UUID
A 5 minutes story written on Oct 2017 by Adrian B.G.

From monolith to cloud series 🌩
A series of articles designed to help developers switch from a monolith to a cloud mindset. The web is full of very good tutorials and examples on Why and How to make the switch, so I decided to focus on the small details.
- Auto Increment to UUID - this article
- Think small
This article focuses on the developers who worked only with numeric auto increment primary keys and need/want to switch to UUID’s.
ID int NOT NULL AUTO_INCREMENT 🔢
Entries in a relational database like MySql/SQL/Oracle are usually identified by an incremental, unique (to table) number int(2232). The server collects the parameters, sends an INSERT(...) statement and the database generates a new ID (the next incremental value) and returns it.
When you begin to scale you may end up with a bottleneck, your MySql master instance, because that is the only entity from your system that can generate a unique identifier.
You already know the benefits of an auto increment PK’s , here is a list of limits:
- need to have access (through a pipeline/API/server/connection) to the master instance
- you depend on 1 instance from 1 server from 1 data-center (latency, availability)
- all the write operations are done in a single location (most of the cases), this leads to a hardware limitation of generating new ID’s
- easy to spoof ID’s (bonus: you can easily find out the number of customers)
- MAX_INT — it’s a long shot, but still …worth mentioning
All of these issues can be mitigated to a degree (ex MySql sharding). To fix all of them you can use UUID’s.

UUID 🍱
An universally unique identifier (UUID) is a 128-bit number used to identify information in computer systems. The term globally unique identifier (GUID) is also used. The size of the UUID can differ on implementations.> UUID can be used in relationship databases and viceversa, auto incrementing in NoSql.
In its canonical textual representation it’s a 32 hexadecimal (base 16) digits, displayed in five groups separated by 4 hyphens: 123e4567-e89b-12d3-a456-426655440000
Some bits represent the UUID version (the algorithm used to generate it), others the variant. Starting from a UUID format you can even add your own logic (bits representing some aspects of your business logic).
To generate the random bytes of the UUID more factors are used to ensure a better entropy like the timestamp and the clock sequence. For more technical details you can read the Official Protocol paper of the UUID. Beware of the implementation you use, not all the libraries respect the standard. I have found some implementations that just use the predictable pseudo-random function found in every language to generate a number.
Basically the UUID/GUID is a random ID, the values are not sequential and anyone can create a new ID.
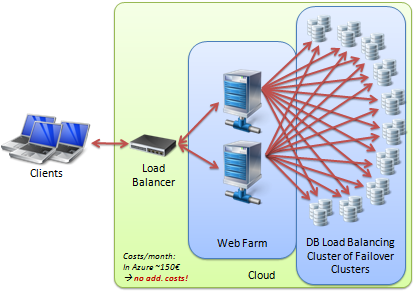
There are a few advantages over a linear incremental value
- it’s easier to shard
- it’s easier to merge/replicate. There is no universal order.
- more flexibility— you can generate UUID’s outside of the database, delegate to servers or clients, environment/platform independent, but you may lose some data integrity
- you can even allow offline register (and sync when available), but you will never have a full DB snapshot (because of the out of sync clients)
- scaling —UUID has a large…r limit of ID’s than an INT
- you know the ID before the insert, it can simplify the logic/flow
- the UUID can have your own format, you can split it in 4 numbers and each one of them represent something else, for example if you group the users from 20 websites, the first number can represent the application.
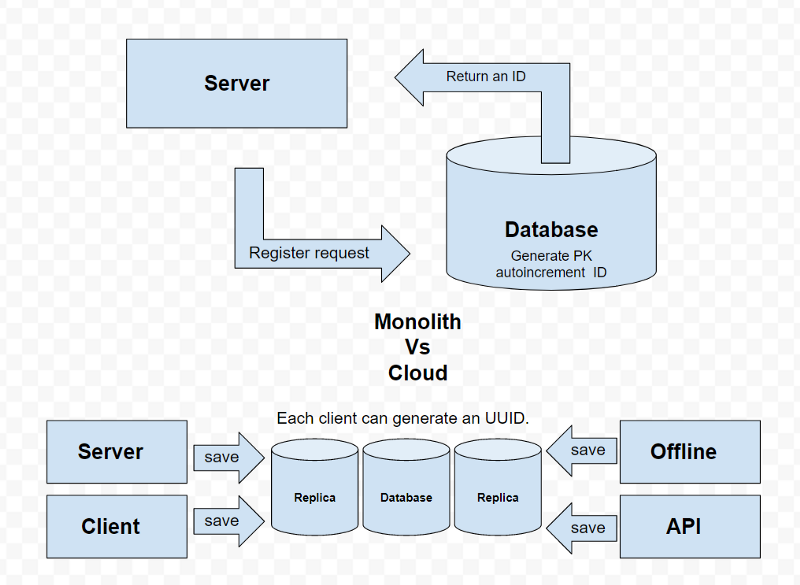
The new mindset 🤕
You will have to get used to a more difficult debugging process, UUID’s are impossible to remember. The trick of memorizing the first or last characters will probably not work.
The change is hard (any change) for the human brain, you will try to fight it, most likely using cheap reasons: an INT is prettier, occupies less storage space. Embrace the change for a greater good, is part of the software evolution.
New factors in town based on async: time and location. An UUID may exists somewhere, but is not synced YET or it’s in other shard. There is no universal sync view anymore. Your production is in chaos now, distribution can mess up your karma, don’t feel frustrated, is just another way of doing stuff.
A few bad things can result of distribution: duplicate or lost data. This means extra coding and extra meetings to explain why and how to the product owners.
I do not think that UUID are universal better or worst than incremental ID’s, they just serve different purposes. But …
I will recommend using UUID’s for any new apps, the current state of software needs demand it (scaling apps, multiple type of clients & platforms, offline apps…).
Before you go, I recommend reading some more:
Software engineer — from monolith to cloud: think small
- Pinterest has a fleet of MySql shards and uses local auto increment ID, in the end they replicate a NoSql (generate UUID’s and store json). Same as Twitter and Facebook they used the wrong technologies from the start and tried to patchup things as their product got bigger. Sharding Pinterest: How we scaled our MySQL fleet
- The caveats and issues with UUID in production: UUID or GUID as Primary Keys? Be Careful!
- General comparison between the most used NoSQL storage solutions: Cassandra vs MongoDB vs CouchDB vs Redis vs Riak vs HBase vs Couchbase vs Hypertable vs…
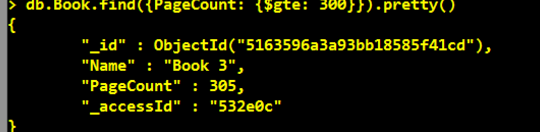
- Generating Globally Unique Identifiers for Use with MongoDB
- ObjectId - MongoDB Manual 3.4
- When are you truly forced to use UUID as part of the design?
- There are specific scenarios when do you need incrementing ID’s, like a queue: Auto Incrementing Keys in NoSql



